News!
- 22.09.2023 OVAD was presented as oral in the Nectar track at GCPR 2023!
- 27.02.2023 OVAD has been accepted by CVPR 2023!
- 24.11.2022 Project page release.
- 23.11.2022 Arxiv paper release

An example of open-vocabulary attribute detection (OVAD). The objective of OVAD is to detect all objects and visual attributes of each object in the image. All base and novel entities are shown in blue and red respectively. All attribute classes are novel and used only for evaluation.
Abstract
Vision-language modeling has enabled open-vocabulary tasks where predictions can be queried using any text prompt in a zero-shot manner. Existing open-vocabulary tasks focus on object classes, whereas research on object attributes is limited due to the lack of a reliable attribute-focused evaluation benchmark. This paper introduces the Open-Vocabulary Attribute Detection (OVAD) task and the corresponding OVAD benchmark. The objective of the novel task and benchmark is to probe object-level attribute information learned by vision-language models. To this end, we created a clean and densely annotated test set covering 117 attribute classes on the 80 object classes of MS COCO. It includes positive and negative annotations, which enables open-vocabulary evaluation. Overall, the benchmark consists of 1.4 million annotations. For reference, we provide a first baseline method for open-vocabulary attribute detection. Moreover, we demonstrate the benchmark's value by studying the attribute detection performance of several foundation models.Dataset
Download data annotation kit and annotations. link
On average, the OVAD benchmark has 98 attribute annotations per object instance, with 7.2 objects per image, for a total of 1.4 million attribute annotations, making it the most densely annotated object-level attribute test dataset.
- 2,000 Test Images
- 117 Attribute Categories
- 80 Object Categories
- 14.3 K Object Instances
- 1.4 M Attribute Annotations
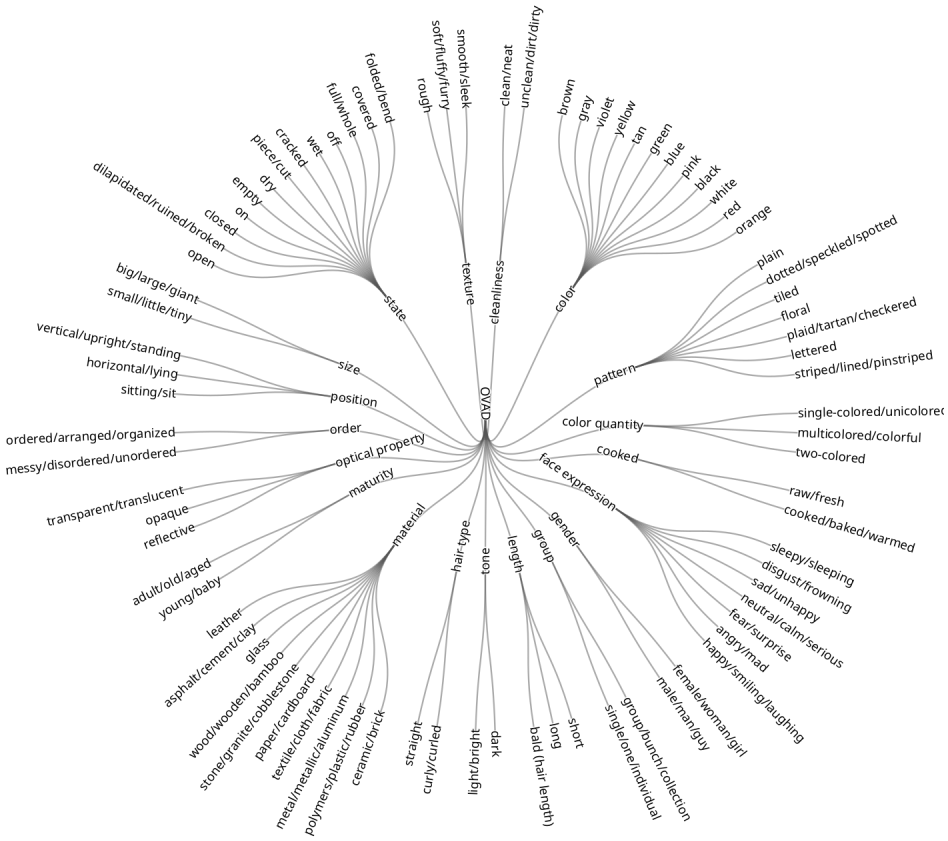
Attribute Hierarchy
Attribute Distribution
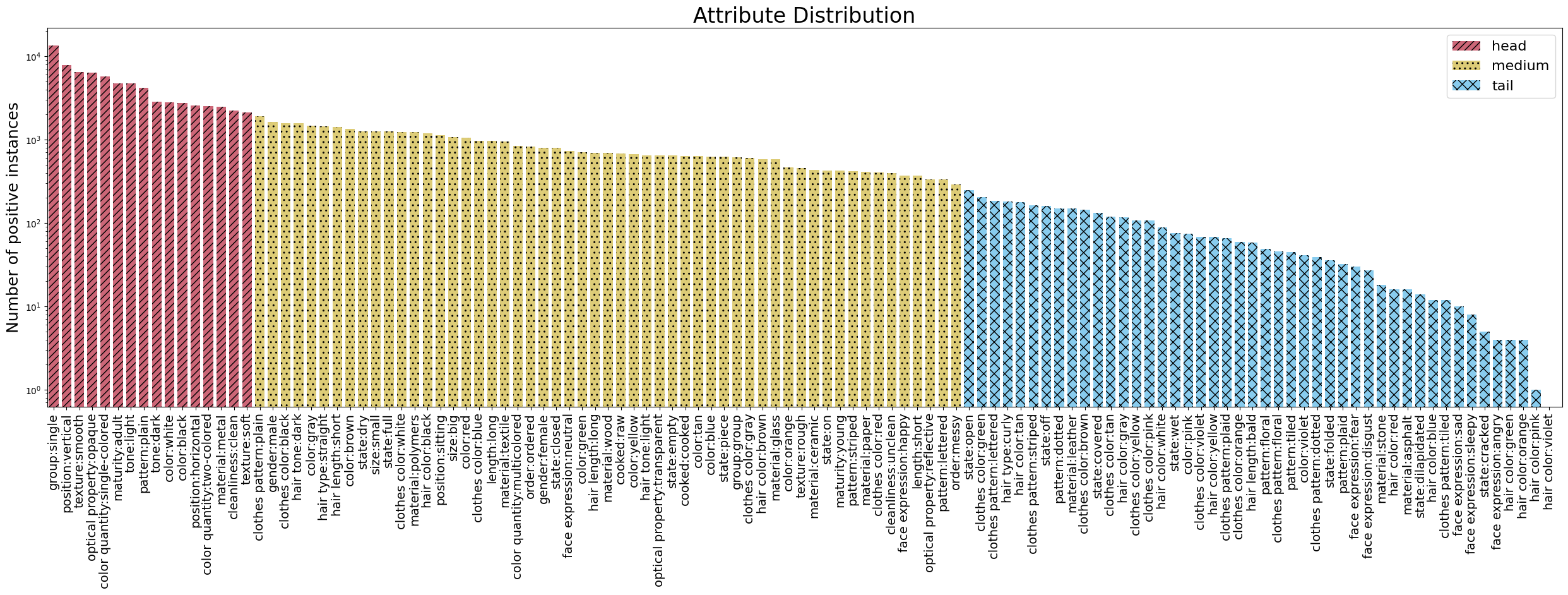
Attribute frequency distribution in the OVAD benchmark. Bar colors correspond to the frequency-defined subsets head, medium and tail.
Benchmark
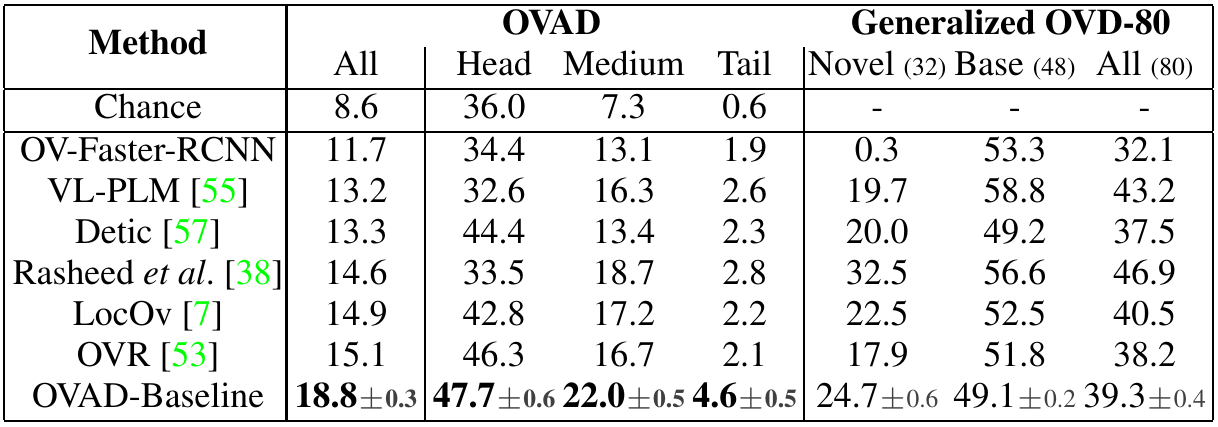
Table 1. mAP on Open-Vocabulary Attribute Detection (OVAD) and AP50 on Open-Vocabulary Detection (OVD-80). Comparing baseline methods across all, head, medium, and tail attributes.
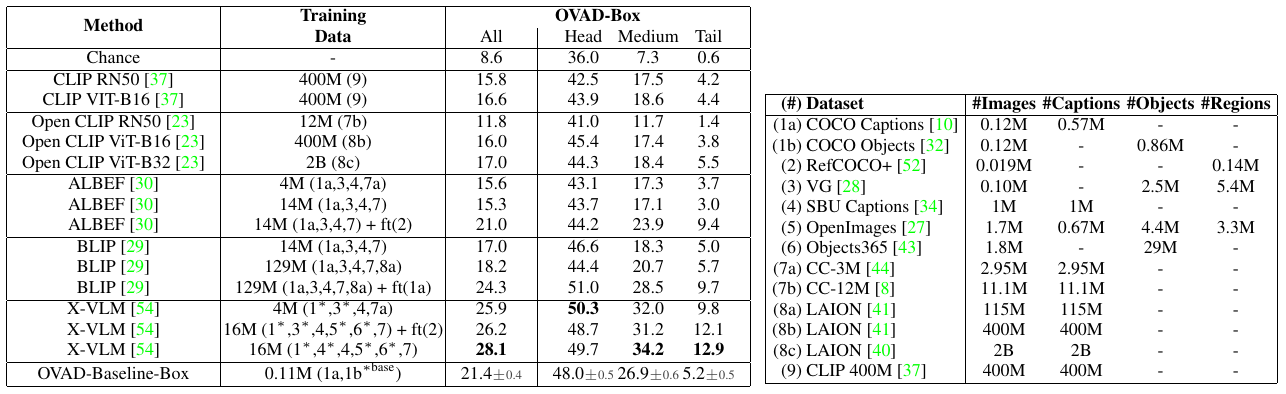
Table 2. Open-vocabulary Attribute Detection results (mAP) for foundation models in the box-oracle setup (OVAD-Box). * The model uses the localization information in the annotations of this dataset. + ft: final fine-tuning pass on the captions of this dataset. Right-side table details the training datasets.
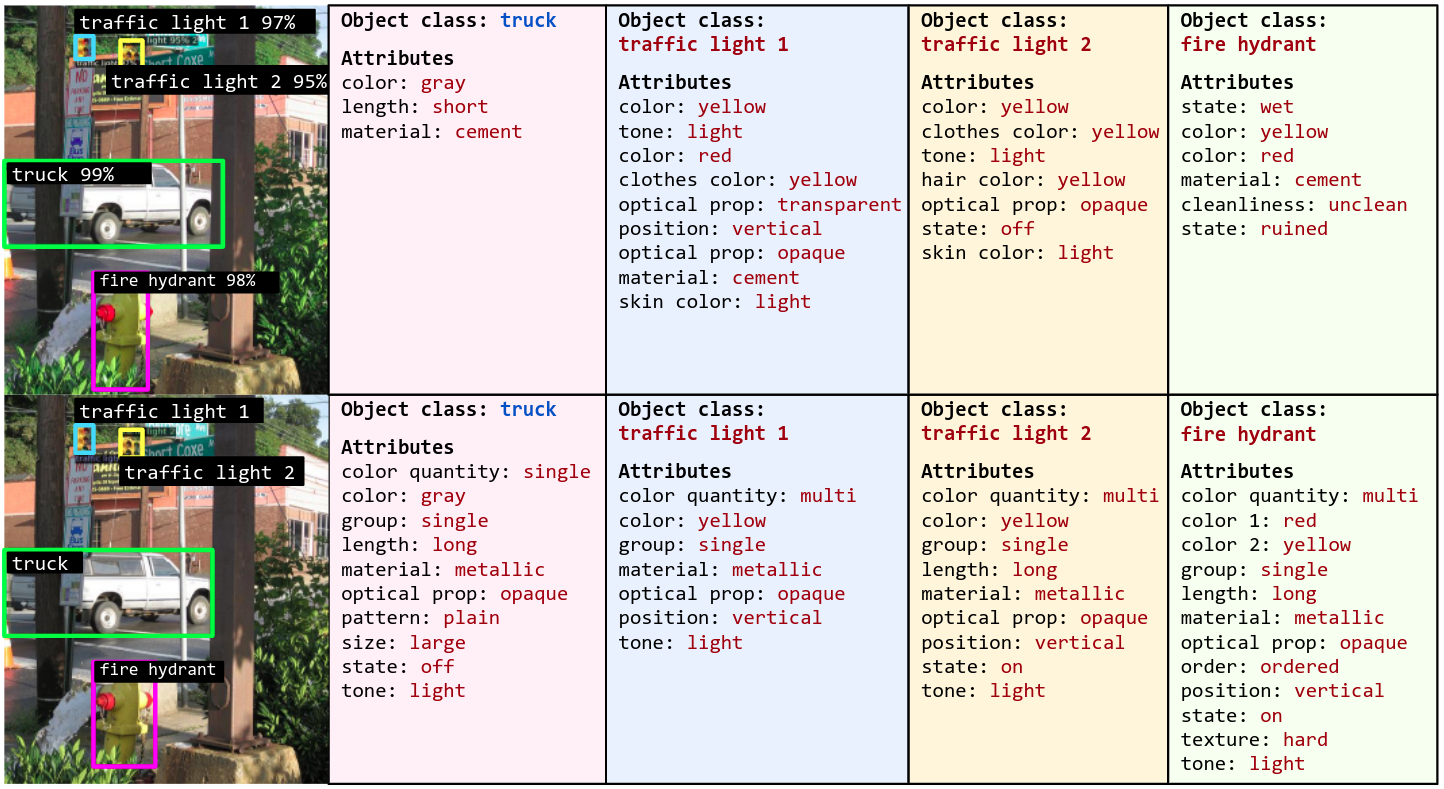
Examples
For each example, top row shows the predictions of the proposed OVAD-Baseline model and bottom row shows the ground-truth.







License

The OVAD
benchmark, annotations along with this website are licensed under a Creative Commons Attribution-NonCommercial-ShareAlike
4.0
International License.
All OVA dataset images come from the COCO dataset; please see
link for their terms of use.